
Vol #24 | What is Amazon Athena for Apache Spark?
Yes, Athena also has a Spark engine!

Hello everyone!
If you are using AWS data and analytics services, you would have used Amazon Athena for querying the data residing in S3 as parquet, CSV, or other file formats. It is super easy to explore data using Athena, and it is one of the most loved tools by different personas, including data engineers, data analysts, and business analysts. You can easily browse the catalog and discover different tables and attributes from the Athena UI.
When you write an SQL in Athena, it executes queries using the Trino engine. Trino is a distributed SQL query engine for big data analytics.
Trino was forked from PrestoDB which was originally created at Facedbook (Meta). Trino was previously known as PrestoSQL and rebranded as Trino in late 2020. If you are interested to know the history of Trino and Presto, you can read it here.
What is Amazon Athena for Apache Spark?
So far, Athena has been all about running SQL queries. However, last year, AWS announced Athena’s support for Apache Spark to process data using the Spark engine. With this feature, you can get a serverless experience for Spark in addition to the existing SQL capabilities.
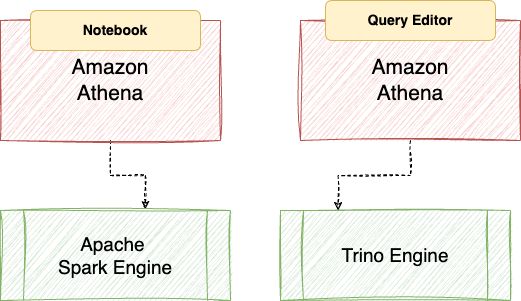
Athena for Spark is one of the easiest ways to run Spark code in AWS. You can create Spark notebooks in Athena, write PySpark code, and execute it seamlessly - without the need to provision any clusters.
Athena gives you the benefit of running Spark serverless so that you don’t have to worry about the underlying infra.
What are the key features?
Some of the key features that Athena for Apache Spark offers:
You can start with Spark within a few seconds; infra-provisioning is not required.
Write PySpark code using notebooks.
Integration with other AWS services like Glue Data Catalog.
Support for open table formats like Apache Hudi, Apache Iceberg, Delta Lake
Single service to ingest and process data using the Spark engine and explore data using the Trino engine.
How can it help you?
The key benefits of using Athena Spark are summarized below:
Running Spark using Athena is one of the simplest ways to run Spark code.
Tables created in Athena Spark notebooks can be queried using the Athena SQL engine.
In-built support for the open table formats makes working with them easier without additional configurations.
You can provide access only to a few services like Athena, S3, and Glue Data Catalog to users who want to process and explore data.
Good alternative to Amazon EMR and AWS Glue ETL.
Use cases for Amazon Athena for Apache Spark?
You might be aware that Amazon EMR is one the most versatile services that offers several big data frameworks, including Spark, Hive, HBase, Presto, and many more. You can get more control over clusters and configurations. However, if you need just Apache Spark to execute lighter workloads, then you can consider Athena for Spark.
Some of the use cases are listed below:
Quick data and analytics PoCs using Spark.
Evaluation of new technologies like open table formats.
Providing fast and easy notebook experience to data scientists.
Alternative to EMR for running ad-hoc Spark workloads.
If you need a visual editor for creating Spark jobs just like the good old Informatica/Datastage days - you can use AWS Glue Studio for drag and drop expereince.
Further Reading
Here is a good detailed blog for using Athena for Spark. It gives step-by-step guidance to create your first notebook.
If you are interested in using Athena for lakehouse implementation, refer to my Medium post.
If you have any further questions about Athena or other AWS data and analytics services, I’ll be happy to get on a call. You can book my time here.